CQRS and Event Sourcing
CQRS
In a traditional distributed system, you have a set of clients who are interacting with a set of services and a backend data store. The interactions with the datastore are generally referred as CRUD operations (Create, Read, Update, Delete).
The backend services which contain the business logic define the data models required for the datastore. Services use the same model for both reading and writing to the datastore.
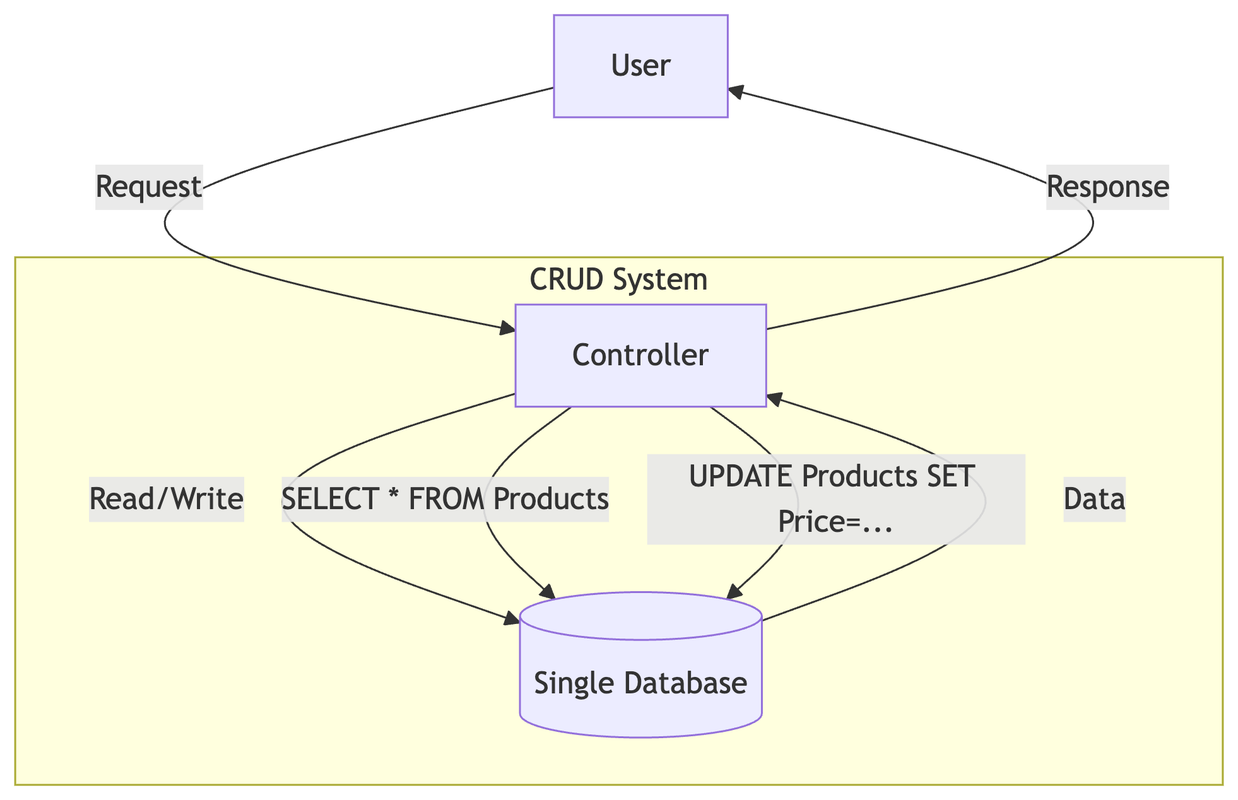
Issues with traditional approach
- Traditioinally, Data models are designed to be write optimized. While reading we often need to do a lot of joins and aggregations to get the data in the format we need. Join and aggregations are resource intensive operations and can cause performance issues.
- In applications which are read heavy, we have to scale the entire system to handle the read traffic. This can be expensive and inefficient.
- With single model, the data modification logic can get intertwined with the data retrieval logic. This can make it difficult to maintain and scale the application. This also make the codebase hard to test, debug and maintain.
CQRS Pattern
The "command" in CQRS refers to operations that modify data, such as creating, updating, or deleting records. These operations are typically handled by a separate component, often called a "command handler."
The "query" in CQRS refers to operations that retrieve data, such as reading records from a database. These operations are typically handled by a separate component, often called a "query handler."

Notice how we have the write database and read database separated in above diagram. This separation helps us to scale the read and write operations independently.
Benefits of CQRS
-
Scalability: By separating the write and read operations, you can scale them independently. For example, you can scale the read operations by adding more read replicas or using a caching layer.
-
Performance: By separating the write and read operations, you can optimize each operation for its specific needs. For example, you can use a write-optimized database for write operations and a read-optimized database for read operations.
-
Flexibility: By separating the write and read operations, you can use different technologies for each operation. For example, you can use a relational database for write operations and a document-based database for read operations.
-
Simplicity: By separating the write and read operations, you can simplify the codebase. For example, you can use a single model for both write and read operations, or you can use a different model for each operation.
Quick Comparison
| CRUD vs. CQRS Architecture Comparison | ||
|---|---|---|
| Aspect | Traditional CRUD | CQRS |
| Database | Single shared database | Separate write/read databases |
| Schema | Compromise for reads+writes | Write: Normalized Read: Denormalized |
| Performance | Reads block writes (and vice versa) | Independent scaling |
| Complexity | Simple but inflexible | More complex but adaptable |
| Use Case | Low-traffic apps | High-scale systems |
| Data Consistency | Strong consistency | Eventual consistency |
| Maintenance | Easier to understand | Requires sync mechanisms |
Sync mechanisms
CQRS pattern requires a way to synchronize data between the write and read databases. There are several ways to achieve this synchronization:
- Change Data Capture (CDC)
- Tracks database changes (inserts/updates/deletes) at the transaction log level.
- Propagates these changes to read models.
- Tools: Debezium (Kafka Connect), SQL Server CDC, PostgreSQL Logical Decoding
Pros:
- Near real-time sync
- Low impact on write DB
- Works with legacy systems
Cons:
- Complex to set up
- Database-specific
- Event driven messaging
- Command side publishes events (e.g., ProductPriceUpdated) to a message broker.
- Query side subscribes and updates read models.
- Tools: Kafka, RabbitMQ, Azure Event Hubs
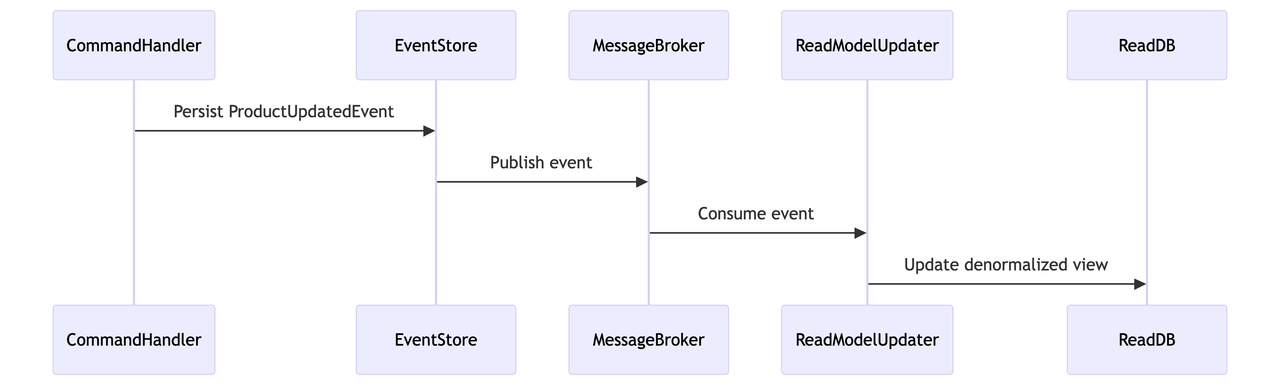
Pros:
- Decouples components
- Scalable (multiple consumers)
- Replayable events
Cons:
- Requires event versioning
- Eventual consistency lag
- Batch Synchronization
- Periodic jobs (e.g., hourly/daily) rebuild read models from source data.
- Transactional Outbox Pattern
- Write changes to an outbox table in the same transaction.
- Separate process polls the outbox and publishes events.
Real world examples
- Uber: Uses Kafka for event streaming between write and read models.
- Netflix: Combines CDC (for DB changes) with Kafka (for business events).
- Banking Systems: Often use transactional outbox for auditability.
Trade offs
| Scenario | Traditional CRUD | CQRS | Tradeoffs |
|---|---|---|---|
| Simple CRUD Apps | ✅ Best fit (e.g., admin dashboards) | ❌ Overkill | CRUD: Simpler code. CQRS: Unnecessary complexity. |
| High-Read Workloads | ❌ Struggles (e.g., analytics) | ✅ Optimized (e.g., product catalogs) | CRUD: Reads block writes. CQRS: Independent read scaling. |
| Complex Business Logic | ❌ Mixed validation/reads | ✅ Isolates rules (e.g., orders) | CRUD: Hard to maintain. CQRS: Needs sync logic. |
| Audit/Compliance Needs | ❌ Manual logging | ✅ Built-in history (with ES) | CQRS+ES: Automatic audit trail. CRUD: Extra effort required. |
| Microservices | ❌ Shared DB coupling | ✅ Decouples via events | CRUD: Hard to scale. CQRS: Needs Kafka/RabbitMQ. |
| Real-Time Dashboards | ❌ Slow joins | ✅ Pre-computed views | CRUD: Poor latency. CQRS: Eventual consistency lag. |
| Legacy Systems | ✅ Easy migration | ❌ High rewrite cost | CRUD: Lower risk. CQRS: Requires full redesign. |
| Team Skill Level | ✅ Junior-friendly | ❌ Needs DDD/ES expertise | CRUD: Faster onboarding. CQRS: Steep learning curve. |
Event Sourcing
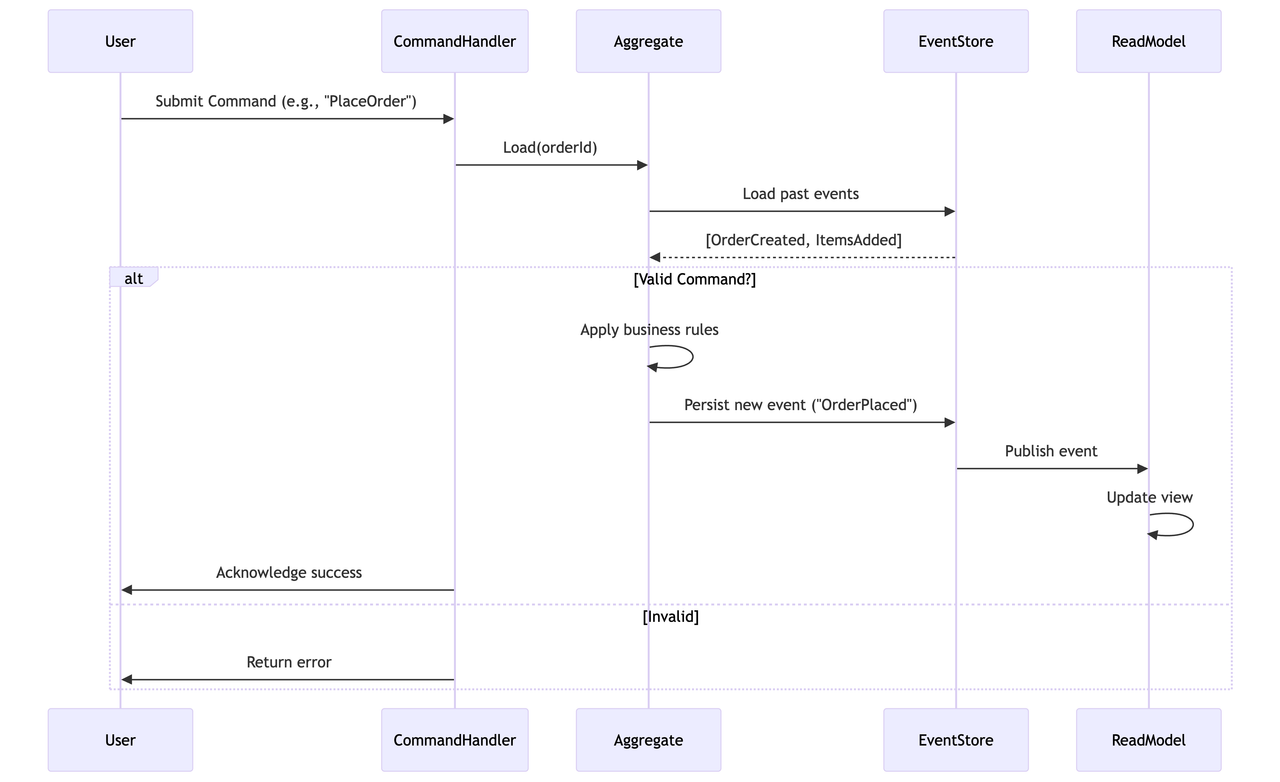
The concept of event sourcing shifts the focus from storing the current state of the system ( in db ) to recording the series of events that occured over time to reach that state.
Here's how it works :
- Every change to the system is captured as a event. Events are immutable and cant be changed.
- Events are persisted in a event store. This store is append only in nature.
- The current state of an entity is derived by replaying the sequence of events that have occurred for that entity.
- For entities with a long history of events, replaying all events every time the current state is needed can be inefficient.
Here's a sample flow :
Why use event sourcing ?
- Auditability : The event store provides a complete history of all changes made to the system, making it easier to track and audit changes.
- Immutable : Events are immutable, which means that once an event is recorded, it cannot be changed or deleted. This makes it easier to maintain a consistent and accurate history of changes.
- Scalability : Event sourcing can help to improve the scalability of a system by allowing the system to handle large volumes of data and transactions.
- Fault tolerance : Event sourcing can help to improve the fault tolerance of a system by allowing the system to recover from failures and continue to operate correctly.