Caching in Distributed Systems
Caching is a technique used to improve the performance of an application by storing frequently accessed data in a cache (memory), which can be accessed faster than retrieving the data from the original source (usually a database).
In distributed caching, instead of relying on a single, potentially overloaded cache instance, the caching responsibility and the cached data are spread out across a cluster of machines.
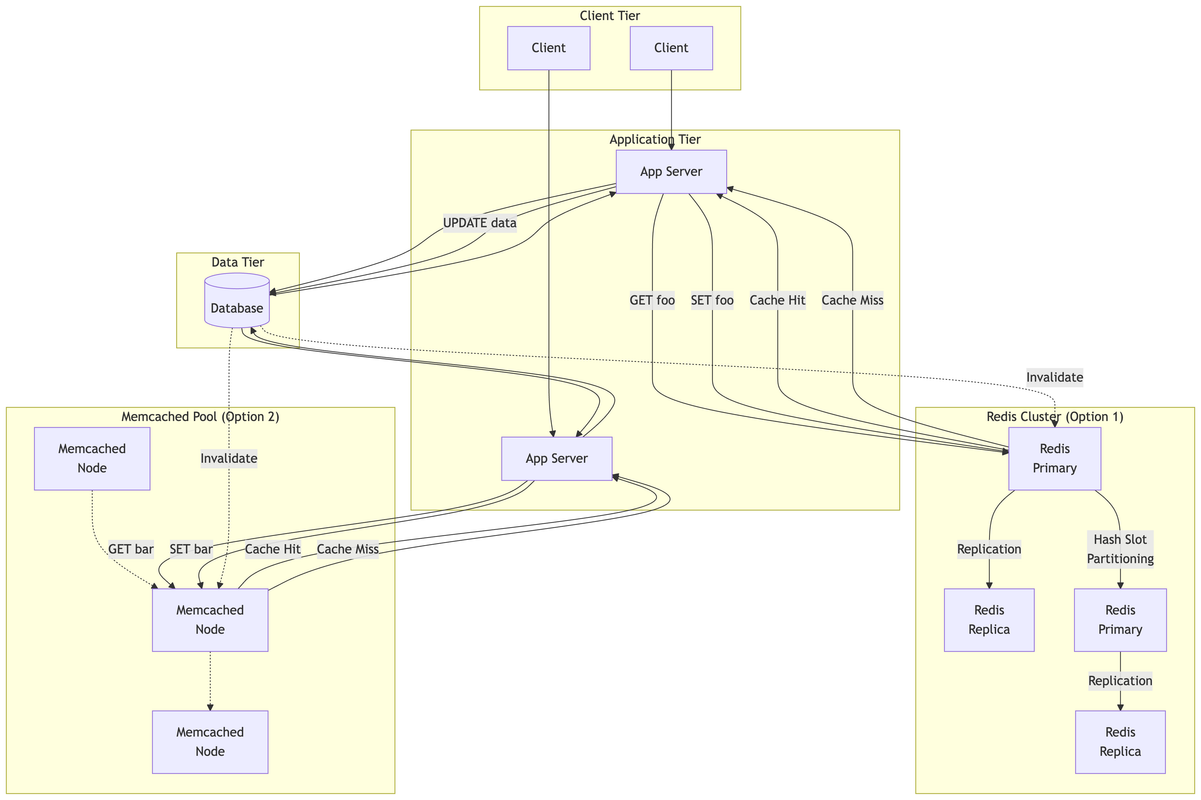
How does it work ?
- Data partitioning
The cache is divided into multiple partitions, each of which is managed by a separate cache node. A mechanism is used to determine which cache node should store a particular piece of data. Common techniques include:
- Consistent Hashing: Distributes data evenly and minimizes data movement when nodes are added or removed.
- Range-Based Partitioning: Data is divided into ranges based on keys.
- Modulus Hashing: A hash of the key is used to determine the node based on the number of nodes.
- Client Interaction
Applications interact with the distributed cache through a client library. The client is responsible for determining which cache node holds the requested data and routing the request accordingly.
- Cache Operations
Standard cache operations like get, set, and delete are performed against the distributed cache.
- Data Replication (Optional)
For increased availability and fault tolerance, data can be replicated across multiple cache nodes
Caching Strategies
- Cache-Aside Pattern
The application handles reading from and writing to both the cache and the main data store. It checks the cache first (cache hit), if not found (cache miss), it fetches from the database, stores it in the cache, and then returns it.
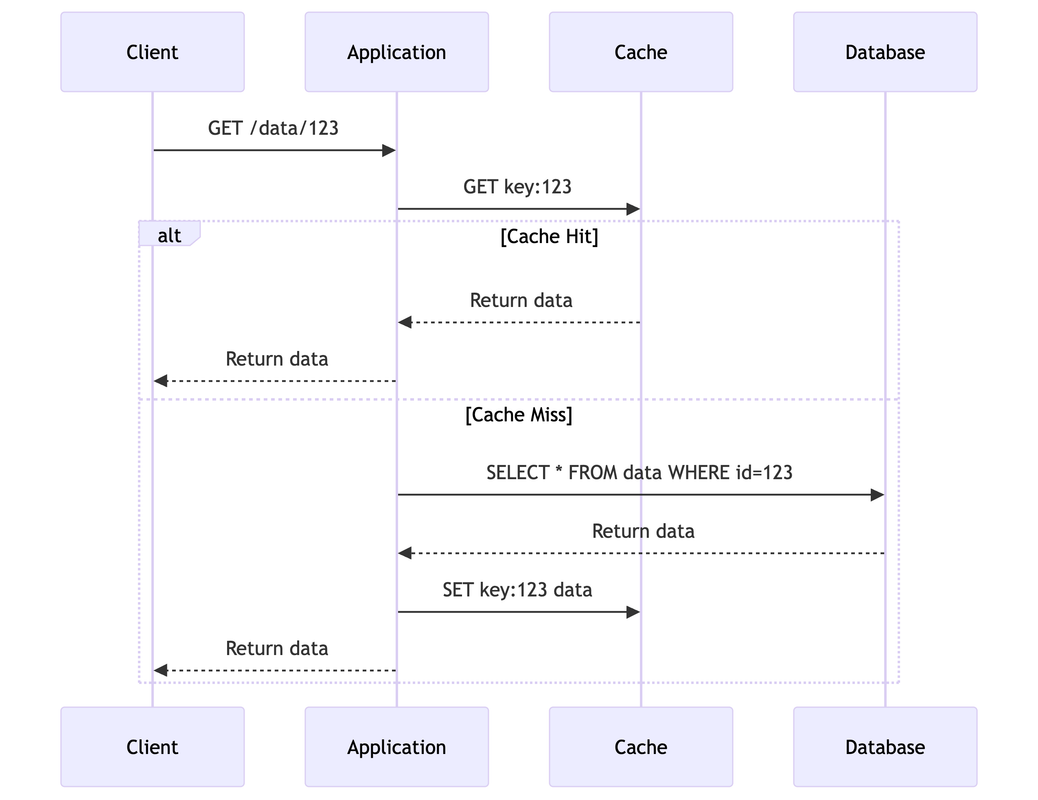
Use When: Read-heavy workloads, simple implementations.
- Read Through Pattern
The cache acts as an intermediary. The application only interacts with the cache. If data is not in the cache on a read, the cache fetches it from the database and then returns it to the application.
- Write Through Pattern
When the application writes data, it's simultaneously written to both the cache and the main data store.
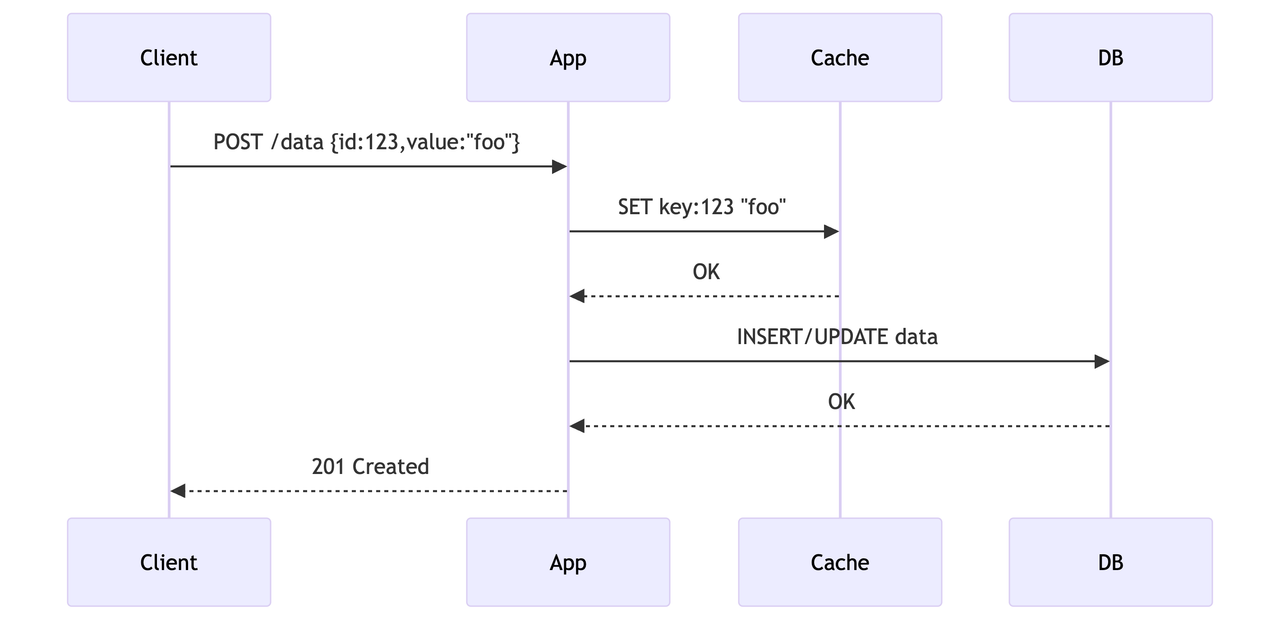
Use When: Data consistency is critical.
- Write Behind Pattern
Writes are initially made only to the cache. The cache then asynchronously updates the database after a delay or under certain conditions. This can improve write performance but introduces data consistency challenges.
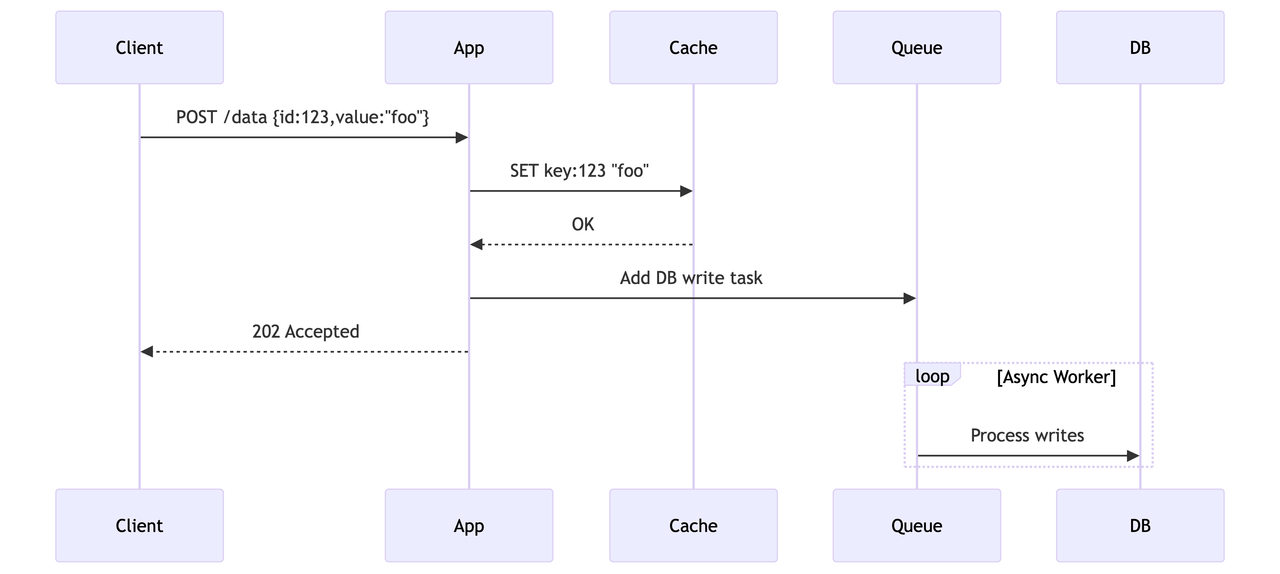
Use When: Write-heavy systems that can tolerate eventual consistency.
Redis (Remote Dictionary Server)
Redis is a key-value in-memory data store. It can be used as a cache, message broker and a database as well.
Redis supports a wide range of data structures, including strings, hashes, lists, sets, sorted sets, bitmaps, hyperloglogs, and geospatial indexes.
For every key stored in Redis, you can set a time to live (TTL) in seconds. Once the TTL expires, the key is automatically deleted.
TTL is just one of cache eviction policies. Redis supports several other eviction policies, such as:
- noeviction: the server refuses to write any new data if the memory limit is reached.
- allkeys-lru: the server removes the least recently used keys.
- allkeys-random: the server removes a random key.
and more.
Here's which data structure to use in redis based on your use case:
- Hashes: Ideal for caching objects with multiple fields, allowing you to fetch individual fields if needed using hget.
- Lists: Can be used for caching ordered data, like the latest blog posts. You can use lpush to add new items and lrange to retrieve a range. Be mindful of list size to avoid memory issues.
- Sets: Useful for caching unique IDs or tags associated with an item.
- Sorted Sets: Can be used for caching ranked lists, where the score determines the order.
Best practices for redis caching
- Keep track of hot data. Focus on caching data that is frequently accessed and relatively static.
- Set appropriate TTLs. Choose TTL values that balance freshness with cache hit rate.
- When caching complex objects, serialize them (e.g., using JSON.stringify) before storing and deserialize when retrieving.
- Implement robust logic to fetch data from the primary source when a cache miss occurs, avoiding performance bottlenecks.
- Track hit rates and miss rates to evaluate the effectiveness of your caching strategy.
- Monitor Redis memory consumption and configure eviction policies appropriately to prevent out-of-memory errors.
- Use Redis commands like mget and mset to perform multiple operations in a single round trip, improving efficiency.
Redis cluster
Redis Cluster is a distributed implementation of Redis that allows you to scale your Redis deployment across multiple machines. It provides high availability, fault tolerance, and automatic partitioning of data across nodes.
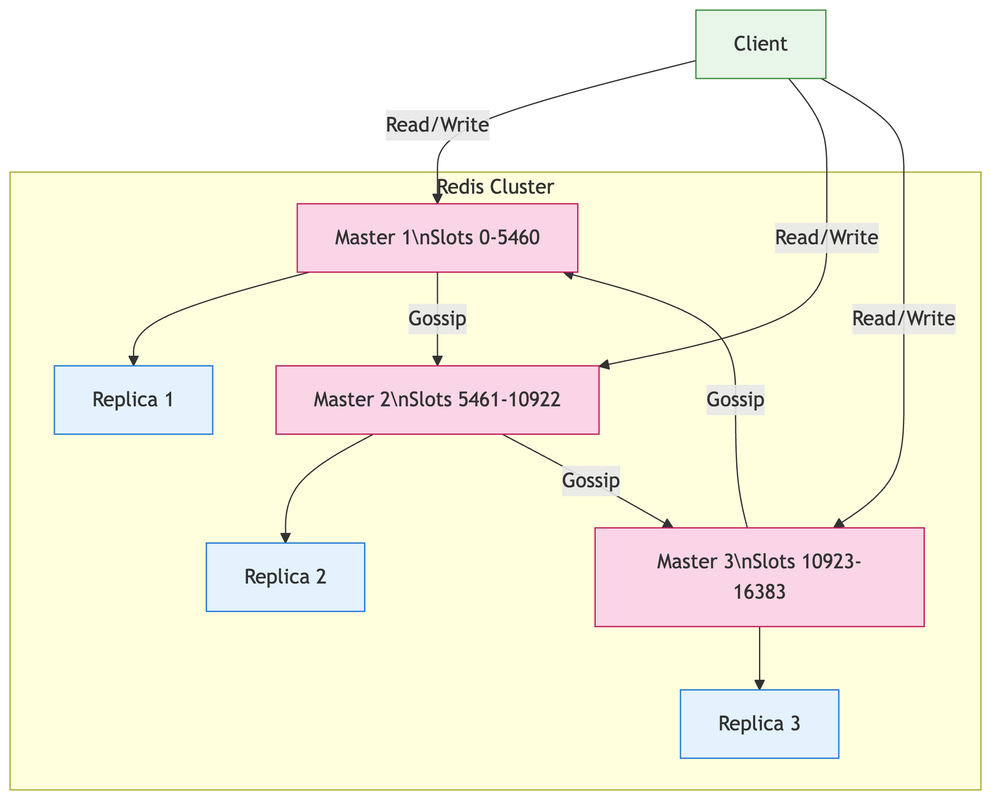
In Redis Cluster, "gossip" refers to the communication protocol that nodes use to exchange cluster state information with each other. This gossip protocol is used to maintain the cluster state, detect failures, and ensure that all nodes have the same view of the cluster.
Gossip protocol in action -
When a new node joins:
- It tells a few nodes "I exist"
- Those nodes tell others
- Within seconds, the whole cluster knows
During failover:
- When a master fails, its replica broadcasts this change
- Other nodes update their cluster maps
Redis vs Memcached
| Feature | Redis | Memcached | Trade-offs | Best Use Cases |
|---|---|---|---|---|
| Data Model | Rich data structures (strings, hashes, lists, sets, sorted sets) | Simple key-value only | Redis offers more flexibility, Memcached is simpler | Redis: Complex data needs. Memcached: Simple caching |
| Persistence | Supports disk persistence (RDB/AOF) | Purely in-memory | Redis survives restarts, Memcached is faster | Redis: Critical data. Memcached: Transient cache |
| Performance | ~100k ops/sec (single-threaded) | ~1M ops/sec (multi-threaded) | Memcached better for raw throughput | Redis: Complex ops. Memcached: Simple gets/sets |
| Memory Efficiency | Higher overhead (~96 bytes per key) | More efficient (~56 bytes per key) | Memcached better for large key counts | Redis: Rich features. Memcached: Max key density |
| Clustering | Built-in Redis Cluster | No built-in clustering | Redis scales better horizontally | Redis: Large datasets. Memcached: Single-node caching |
| Threading Model | Single-threaded (with I/O threads in Redis 6+) | Multi-threaded | Memcached better utilizes multi-core | Redis: Consistency. Memcached: Parallel ops |
| Data Size Limits | Max 512MB per value | Default 1MB per value (configurable) | Redis allows larger values | Redis: Big data items. Memcached: Small cache items |
| Advanced Features | Pub/sub, transactions, Lua scripting, geospatial | None - pure cache | Redis for complex needs | Redis: Real-time systems. Memcached: Simple cache |