A software engineer's guide to kafka
Tradionally when multpiple services in a distributed system needed to communcicate, they used direct point to point communication or more recently the message queues.
Both of these patterns created a tight coupling between services and made it difficult to scale and maintain the system.
Without Kafka, building a system where many independent services can reliably and scalably exchange and process continuous streams of data in real-time, while also allowing for independent consumption and historical data access, would be incredibly complex and require significant custom engineering. Kafka provides a robust and well-engineered platform to solve these challenges.
Here's a quick illustration of all the components involved in a Kafka system:
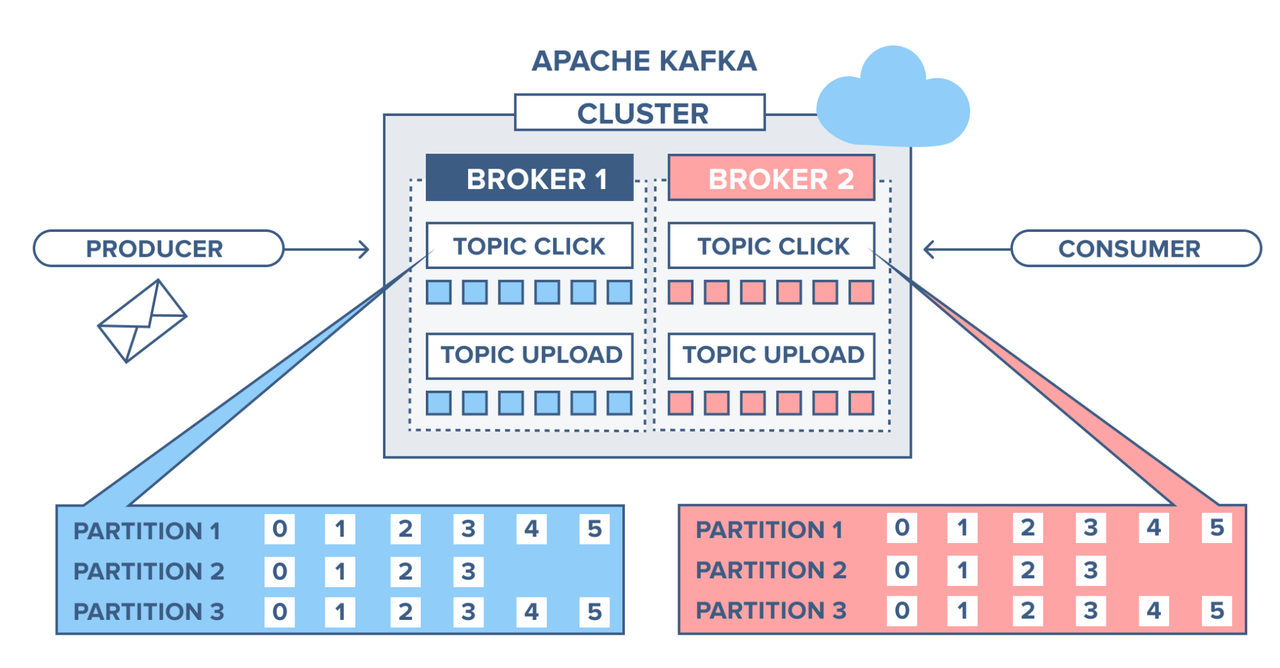
Core concepts in Kafka
- Topics
Topics are basic building blocks in kafka. They are like folders in a file system. Topics are used to group related messages together.
All data related to one domain or use case are grouped under one topic. For example, all the messages related to user registration can be grouped under a topic called 'user-registration'.
Imagine a newspaper. It has different sections like "Sports," "World News," "Business," etc. In Kafka, topics are like these sections. Each section has its own content, and you can access it independently.
When producers publish messages, they publish it to a specific topic. Consumers subscribe to topics and consume messages from them.
Topic names are strings and should be chosen to be descriptive of the data they contain. Kafka itself doesn't enforce a specific schema on the data within a topic. Producers can publish messages in various formats (e.g., JSON, Avro, plain text).
- Partitions
Each topic is divided into one or more partitions. Each partition stores a ordered sequence of immutable messages or records.
All messages within a partition are strictly ordered by their offset.
- Offsets
An offset is a unique identifier for a message within a partition. Consumers use offsets to track their position within a partition.
Offsets are essentially sequential numbers and only relevant within the context of a specific partition.
- Brokers
A broker is a basically a server. Collection of brokers form a kakfa cluster. Every broker is responsible for storing a one or more partitions of a topic.
Each broker hosts a subset of the partitions of all the topics in the cluster. A single broker can host multiple partitions, and a single partition can be hosted by multiple brokers.
Brokers are stateless in nature and do not store any metadata about the data they host. This metadata is stored in a separate metadata server called Zookeeper.
When you instantiate KafkaProducer or KafkaConsumer, you provide a list of bootstrap_servers. These are the initial brokers your client will connect to. The client then discovers the other brokers in the cluster from these initial connections. You don't typically interact with individual brokers directly in your application logic. The client library handles the communication with the cluster.
- Producers
Producers are client applications that publish messages to topics. They can optionally provide the particition key to send the message to a specific partition. If no partition key is provided, the message is sent to a random partition.
Producers can configure the level of acknowledgement they require from the Kafka brokers before considering a write successful. This allows them to trade off between latency and durability.
- acks=0: The producer doesn't wait for any acknowledgement. Lowest latency but highest risk of data loss.
- acks=1: The producer waits for acknowledgement from the leader broker. Good balance between latency and durability.
- acks=all or acks=-1: The producer waits for acknowledgements from all in-sync replicas (ISR). Highest durability but also higher latency.
Producers are responsible for serializing the data they send to Kafka. They can use various serialization formats like JSON, Avro, or plain text.
When you create a KafkaProducer instance, you specify the bootstrap_servers (the address of one or more Kafka brokers). When you send a message using producer.send(), you explicitly provide the topic name as an argument. This tells the producer which logical stream of data you want to write to.
- Consumers
Consumers are client applications that subscribe to topics and consume messages from them. Each consumer belongs to a consumer group.
Each partition of a topic is assigned to one consumer in a consumer group. This ensures that each consumer in the group consumes messages from a different partition.
Consumers track the offsets based on the last message they have consumed successfully. Consumers are responsible for deserializing the data they receive from Kafka.
When you create a KafkaConsumer instance, you specify the topic name you want to consume from. You can also specify other parameters like the bootstrap_servers, auto_offset_reset, enable_auto_commit, and group_id.
- Zookeeper
Zookeeper is a centralized service that manages the metadata for the Kafka cluster. It stores information about the topics, partitions, and brokers. It also handles leader election for partitions.
Try it yourself
Benefits of using kafka
- High throughput: Kafka is designed to handle high volumes of data. It can handle millions of messages per second.
- Scalability: Kafka is designed to be scalable. You can add more brokers to a Kafka cluster to handle more data.
- Durability: Kafka is designed to be durable. It uses a log-structured storage system. This means that data is written to disk and then committed to the log. This ensures that data is not lost even if the broker fails.
- Fault tolerance: Kafka is designed to be fault tolerant. If a broker fails, Kafka can automatically reassign the partitions to other brokers.
- High availability: Kafka is designed to be highly available. It uses a quorum-based replication mechanism. This means that a majority of the brokers in the cluster must be available for Kafka to function.
When to use kafka vs When to not use kafka
| Consideration | Use Kafka When... | Tradeoffs / Potential Downsides | Consider Alternatives When... |
|---|---|---|---|
| Complexity & Setup | Building complex, scalable, and fault-tolerant data pipelines and event-driven architectures is a primary goal. You have the resources and expertise to manage a distributed system. | Increased operational complexity (managing brokers, Zookeeper/KRaft, monitoring), steeper learning curve for development teams, potentially higher infrastructure costs. | Your needs are simple and don't require the advanced features of Kafka. Simpler messaging systems (e.g., RabbitMQ for task queues, direct HTTP calls for request/response) might suffice with less overhead. |
| Scalability Needs | You anticipate significant growth in data volume and the number of consumers, requiring horizontal scaling capabilities for both ingestion and processing. | Scaling Kafka effectively requires careful planning (partitioning strategy, consumer group management). Misconfiguration can lead to performance bottlenecks. | Your system has predictable and relatively low scaling needs. Vertical scaling of application instances might be sufficient. |
| Throughput Requirements | You need to handle high-velocity data streams with low latency for real-time processing and analytics. | Achieving optimal high throughput often requires careful tuning of Kafka configurations (broker settings, producer/consumer parameters) and network infrastructure. | Your data volume is low, and latency is not a critical concern. Simpler systems might offer acceptable performance with less tuning. |
| Reliability & Durability | Data loss is unacceptable, and you need strong guarantees of message delivery (at least once, exactly once with transactional producers/consumers). You require durable storage and fault tolerance. | Achieving "exactly once" semantics can introduce complexity and potentially impact performance. Replication increases storage costs. | Occasional data loss is tolerable, or reliability is handled at the application level. Simpler, less durable messaging systems might be acceptable. |
| Decoupling Benefits | You need to decouple producers and consumers for independent scaling, development, and deployment. Different consumers need to process the same data in different ways without impacting producers. | Introducing an intermediary like Kafka adds a network hop, potentially increasing overall system latency (though Kafka is designed for low latency). | Your services have inherent, tight dependencies, and the benefits of loose coupling are minimal. Direct communication might be simpler to implement and manage. |
| Data Retention & Replay | You need to retain data for a certain period for auditing, reprocessing, or onboarding new consumers. The ability to replay historical data is valuable. | Storing large volumes of data in Kafka can lead to increased storage costs. Managing data retention policies requires configuration and monitoring. | You don't need to retain data after processing, or data retention is handled by other systems (e.g., databases). Message replay is not a requirement. |
| Complexity of Use Cases | Building complex stream processing applications (using Kafka Streams or other stream processing engines integrated with Kafka), handling event sourcing, or implementing CQRS patterns. | Integrating Kafka with stream processing frameworks adds another layer of complexity. Designing and implementing these advanced patterns requires a deep understanding of both Kafka and the chosen framework. | Your use cases are simple message queuing or basic pub/sub without complex processing requirements. Simpler message brokers might be easier to integrate. |