Implmenting Bloom filters in JS
If you have been programming, you must be familiar with & have used different data structures like arrays, linked lists, trees, etc. Bloom
filters are also a type of data structure. Its a data structure thats is used to check if an element is
present in a set or not.
Bloom filters were originally invented to solve space efficiency problems. In the 1970s, memory was scarse and storing a
larrge amount of data in memory was a impractical.
How does a bloom filter work ?
Bloom filters consist of a bit array and a set of hash functions. All bits in the array are initialized to 0. Adding a new value to the bloom filter involves computing the hash values of the value using the hash functions and setting the corresponding bits in the bit array to 1.
When we want to check if a value is present in bloom filter or not, we again compute the hash values of the value using the hash functions and check if all the corresponding bits in the bit array are set to 1.
If all the bits are set to 1, then the value is present in the bloom filter. If any of the bits are not set to 1, then the value is not present in the bloom filter.
So simply said, if bloom returns false for a lookup value,
then the value is definitely not present in the bloom filter. But if bloom returns true for a lookup vaule, then the value might be present in the bloom filter.
Here's a quick illustration:
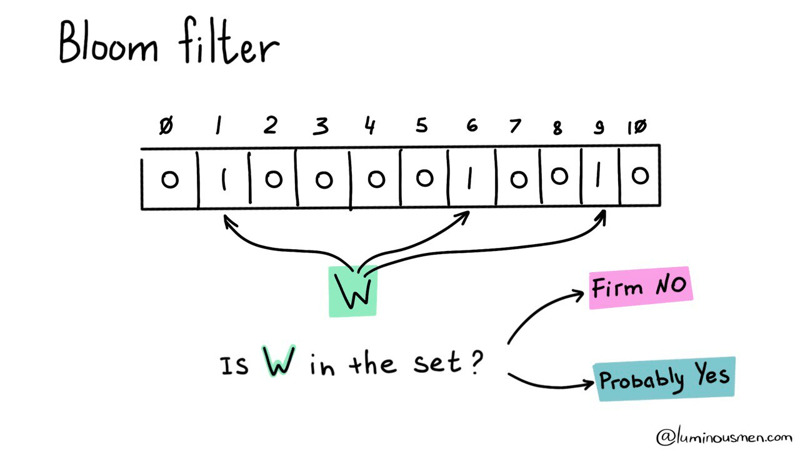
source
Building spell checker using bloom filters
Here's a simple example of building a spell checker using bloom filters.
class BloomFilter {
constructor(size = 1000, numHashes = 3) {
this.size = size; // Size of the bit array
this.numHashes = numHashes; // Number of hash functions
this.bitArray = new Array(size).fill(0); // Initialize all bits to 0
}
// Basic hash functions (for simplicity, we use a few different hash methods)
hash1(word) {
let hash = 0;
for (let i = 0; i < word.length; i++) {
hash = (hash << 5) + hash + word.charCodeAt(i);
hash = hash & hash; // Convert to 32-bit integer
hash = Math.abs(hash);
}
return hash % this.size;
}
hash2(word) {
let hash = 5381;
for (let i = 0; i < word.length; i++) {
hash = (hash * 33) ^ word.charCodeAt(i);
}
return Math.abs(hash) % this.size;
}
hash3(word) {
let hash = 0;
for (let i = 0; i < word.length; i++) {
hash = (hash << 3) + word.charCodeAt(i);
hash = hash & hash;
}
return Math.abs(hash) % this.size;
}
// Insert a word into the Bloom Filter
add(word) {
const indices = [
this.hash1(word),
this.hash2(word),
this.hash3(word),
].slice(0, this.numHashes); // Use first `numHashes` hashes
indices.forEach((index) => {
this.bitArray[index] = 1;
});
}
// Check if a word *might* be in the set (may have false positives)
contains(word) {
const indices = [
this.hash1(word),
this.hash2(word),
this.hash3(word),
].slice(0, this.numHashes);
return indices.every((index) => this.bitArray[index] === 1);
}
}
class BloomFilter {
constructor(size = 1000, numHashes = 3) {
this.size = size; // Size of the bit array
this.numHashes = numHashes; // Number of hash functions
this.bitArray = new Array(size).fill(0); // Initialize all bits to 0
}
// Basic hash functions (for simplicity, we use a few different hash methods)
hash1(word) {
let hash = 0;
for (let i = 0; i < word.length; i++) {
hash = (hash << 5) + hash + word.charCodeAt(i);
hash = hash & hash; // Convert to 32-bit integer
hash = Math.abs(hash);
}
return hash % this.size;
}
hash2(word) {
let hash = 5381;
for (let i = 0; i < word.length; i++) {
hash = (hash * 33) ^ word.charCodeAt(i);
}
return Math.abs(hash) % this.size;
}
hash3(word) {
let hash = 0;
for (let i = 0; i < word.length; i++) {
hash = (hash << 3) + word.charCodeAt(i);
hash = hash & hash;
}
return Math.abs(hash) % this.size;
}
// Insert a word into the Bloom Filter
add(word) {
const indices = [
this.hash1(word),
this.hash2(word),
this.hash3(word),
].slice(0, this.numHashes); // Use first `numHashes` hashes
indices.forEach((index) => {
this.bitArray[index] = 1;
});
}
// Check if a word *might* be in the set (may have false positives)
contains(word) {
const indices = [
this.hash1(word),
this.hash2(word),
this.hash3(word),
].slice(0, this.numHashes);
return indices.every((index) => this.bitArray[index] === 1);
}
}
Here's how you can use this:
// Initialize Bloom Filter
const bloomFilter = new BloomFilter(1000, 3);
// Add correct words to the "dictionary"
const dictionary = ["apple", "banana", "cherry", "date", "elderberry"];
dictionary.forEach(word => bloomFilter.add(word));
// Test words for spelling
const testWords = ["apple", "banana", "kiwi", "date", "mango"];
testWords.forEach(word => {
const exists = bloomFilter.contains(word);
console.log(`"${word}" is ${exists ? "probably correct" : "definitely wrong"}`);
});
// Initialize Bloom Filter
const bloomFilter = new BloomFilter(1000, 3);
// Add correct words to the "dictionary"
const dictionary = ["apple", "banana", "cherry", "date", "elderberry"];
dictionary.forEach(word => bloomFilter.add(word));
// Test words for spelling
const testWords = ["apple", "banana", "kiwi", "date", "mango"];
testWords.forEach(word => {
const exists = bloomFilter.contains(word);
console.log(`"${word}" is ${exists ? "probably correct" : "definitely wrong"}`);
});
Here's the output of this code:
"apple" is probably correct
"banana" is probably correct
"kiwi" is definitely wrong (correct, not in dictionary)
"date" is probably correct
"mango" is definitely wrong (correct, not in dictionary)
"apple" is probably correct
"banana" is probably correct
"kiwi" is definitely wrong (correct, not in dictionary)
"date" is probably correct
"mango" is definitely wrong (correct, not in dictionary)
When to use bloom filters ?
- When you need extreme space efficiency e.g A Bloom filter can represent a 1-million-word dictionary in ~1MB (with a 1% false-positive rate), while a hash set would require 10–100× more memory.
- When avoiding expensive lookups is critical e.g DB lookups, disk lookups, CDN lookups
- When false positives are acceptable e.g. url blocking, ad blocking, recommendation system
When to NOT use bloom filters ?
| Situation | Why Not to Use Bloom Filters | Alternative |
|---|
| False positives are unacceptable | Bloom filters are probabilistic | Hash sets, trees |
| Need to delete elements | Standard Bloom filters do not support deletion | Counting Bloom filter, hash set |
| Need to enumerate or retrieve elements | Cannot list or retrieve elements | Hash set, list, tree |
| Dataset is small | Overhead outweighs benefits | Hash set, bit array |
| Memory access patterns are critical | Can cause cache misses, slowdowns | Hash set, optimized arrays |
| Set size is unknown or unbounded | False positive rate grows with overfill | Scalable Bloom filters, hash set |
| Need to store actual data | Only stores membership, not data | Hash set, map |
Who is really using bloom filters ?
- Akamai uses bloom filters for optimizing edge caching by filtering the content which are accessed only once.
- Chrome browser uses bloom filters for validating malicious URLs on client side.
- Brave browser uses uses Bloom filters to efficiently check if a domain is in a blocklist for blocking ads.
- Google BigTable uses bloom filters to reduce the number of disk seeks for non existing rows.
- Dropbox uses bloom filters to check if a file chunk is already present in disk ( file dedup ).